Em teoria da probabilidade e estatística, a distribuição beta é uma família de distribuições de probabilidade contínuas definidas no intervalo parametrizado por dois parâmetros positivos, denotados por e , que aparecem como expoentes da variável aleatória e controlam o formato da distribuição.
A distribuição beta tem sido aplicada para modelar o comportamento de variáveis aleatórias limitadas a intervalos de tamanho finito em uma grande quantidade de disciplinas.
Em Inferência bayesiana, a distribuição beta é a distribuição conjugada a priori da distribuição de Bernoulli, distribuição binomial, distribuição binomial negativa e distribuição geométrica. Por exemplo, a distribuição beta pode ser usada na análise bayesiana para descrever conhecimentos iniciais sobre a probabilidade de sucesso assim como a probabilidade de que um veículo espacial vai completar uma missão especificada. A distribuição beta é um modelo conveniente para comportamento aleatório de porcentagens e proporções.
Esta definição inclui os dois extremos e , que é consistente com as definições para outras distribuições contínuas suportadas em um intervalo limitado que são casos especiais da distribuição beta, por exemplo a distribuição arcoseno, e consistente com diversos autores, como N. L. Johnson e S. Kotz.[1][2][3][4] Entretanto, a inclusão de e não funciona para ; diversos autores, incluindo W. Feller,[5][6][7] escolheram excluir os extremos e (portanto, os dois extremos não são realmente parte do domínio da função de densidade) e considerar ao invés .
Diversos autores, incluindo N. L. Johnson e S. Kotz,[1] usam os símbolos e (ao invés de e ) para os parâmetros da distribuição de beta, reminiscente dos símbolos tradicionalmente usados dos parâmetros da distribuição de Bernoulli, porque a distribuição beta se aproxima da distribuição de Bernoulli no limite quando os dois parâmetros e aproxima o valor de zero.
No seguinte, a variável aleatória distribuída sob a distribuição beta com parâmetros e irá ser denotada por :[8][9]
Outras notações são [10] e .[5]
Equação diferencial
A função densidade de probabilidade satisfaz a equação diferencial
A moda da variável aleatória de distribuição beta com , é o valor mais provável da distribuição (correspondendo ao pico na f.d.p.), e é dado pela seguinte expressão:[1]
Quando os dois parâmetros são menores que 1 (, ), isto é a anti-moda: o menor ponto da curva densidade de probabilidade.[3]
Quando , a expressão para a moda é simplificada para , mostrando que para a moda está no centro da distribuição: que é simétrica nesse caso. Veja a seção "Formas" nesse artigo para uma lista completa de casos de moda, para valores arbitrários de e . Para vários desses casos, o valor máximo da função densidade ocorre em um dos dois extremos. Em alguns casos, o valor máximo da função densidade ocorrendo num extremo é finito. Por exemplo, no caso de , (ou , ), a função densidade se torna uma distribuição triangular que é finita nos dois extremos. Em diversos outros casos existe uma singularidade em um dos extremos, onde o valor da função densidade se aproxima do infinito. Por exemplo, no caso , , a distribuição beta simplifica-se para se tornar a distribuição arcoseno. Existe um debate entre matemáticos sobre alguns desses casos e se os extremos ( e ) pode ser chamados de modas ou não.[6][8]
Se os extremos são parte do domínio da função densidade
Se uma singularidade pode alguma vez ser chamada de moda
Se os casos com dois máximos deveriam ser chamados de bimodais
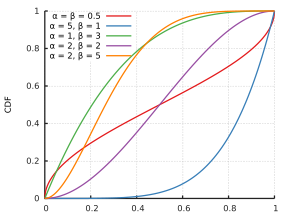
Mediana para a distribuição beta para e (Média - Mediana) para distribuição beta vs. e indo de 0 a 2
Mediana
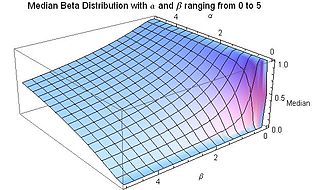
A mediana da distribuição beta é o único número real para o qual a função beta incompleta regularizada . Não existe uma forma fechada para a mediana da distribuição beta para valores arbitrários de e . Algumas formas fechadas para valores particulares dos parâmetros e seguem:
Para casos simétricos, onde , a mediana é igual a
Para e , a mediana é igual a
Para e , a mediana é igual a
Para e , a mediana é igual a solução real da função de quarto grau , que se encontra no intervalo .
Os seguintes são os limites para a mediana da variável aleatória tem um parâmetro finito (não nulo) e o outro se aproximando desses limites:
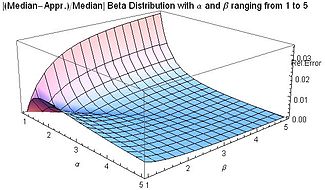
Uma aproximação razoável do valor da mediana da distribuição beta, para ambos e maiores ou iguais a 1, é dado pela fórmula:[11]
Quando , , o erro relativo (o erro absoluto dividido pela mediana) nessa aproximação é menor que 4% e para ambos , é menor que 1%. O erro absoluto dividido pela diferença entre a média e a moda é similarmente pequeno:
para distribuição beta para e para distribuição beta para e
Média para a distribuição beta para e
Média
O valor esperado (média) da variável aleatória sob a distribuição beta com parâmetros e é uma função apenas da razão desses parâmetros:[1]
Fazendo na expressão acima, obtém-se , mostrando que para , a média está no centro da distribuição, que é simétrica. Além dissoos seguintes limites podem ser obtidos da expressão acima:
Portanto, para ou para , a média está localizada no extremo direito, . Para esses limites, a distribuição beta se torna uma distribuição degenerada de um ponto com um pico de função delta de Dirac no extremo direito , com probabilidade 1; e probabilidade 0 em todo o resto do intervalo.
Analogamente, para , ou para , a média é localizada no extremo esquerdo, . A distribuição beta se torna uma distribuição degenerada de um ponto com um pico de função delta de Dirac no extremo esquerdo com probabilidade 1, e 0 em todo o resto do intervalo.
Enquanto para distribuições unimodais típicas (com modas centradas, pontos de inflexão nos dois lados da moda e caudas longas) é conhecido que a média amostral (como uma estimativa de local) não é tão robusta como a mediana amostral, o oposto é o caso para distribuições bimodais uniformes ou "em forma de U" com tal que , , isto é, com as modas localizadas nos extremos da distribuição. Como Mosteller e Tukey frizam[12] "a média das duas observações extremas usa toda a informação amostral. Isto ilustra como, para distribuições de cauda curta, as observações extremas devem receber maior peso". Por contraste, segue que a mediana de uma distribuição bimodal em forma de U com modas nas fronteiras da distribuição (com tal que , não é robusta, conforme a mediana amostral desconsidera as observações amostrais extremas. Uma aplicação prática disso ocorre por exemplo para passeios aleatórios, uma vez que a probabilidade para o tempo da última visita a origem em um passeio aleatório é distribuído como uma distribuição arco seno :[5][13] a média de um número de realizações de um passeio aleatório é um estimador muito mais robusto que a mediana (que é uma medida estimativa amostral inapropriada neste caso).
Média geométrica
(Média- Média geométrica) para distribuição beta versus e de 0 a 2, mostrando a assimetria entre e para a média geométricaMédias geométricas para distribuição beta. Roxo = , amarelo = , com os menores valores e na frenteMédias geométricas para distribuição beta. Roxo = , amarelo = , com os maiores valores e na frente
O logaritmo da média geométrica de uma distribuição da variável aleatória é a média aritmética de ou, equivalentemente, seu valor esperado:
Para a distribuição beta, o valor esperado da integral é:
Assim sendo, a média geométrica de uma distribuição beta com parâmetros e é a exponencial da função digama de e como segue:
Enquanto para a distribuição beta com parâmetros , segue que a curtose = 0 e a moda = média = mediana = , a média geométrica é menor que (isto é: ). A razão para isso é que a transformação logarítmica faz os valores de próximos de zero pesarem muito, enquanto tende rapidamente para menos infinito conforme X se aproxima de zero, enquanto aplaina perto de zero quando .
Ao longo de uma linha , os seguintes limites se aplicam:
Seguindo há os limites com um parâmetro finito (não-nulo) e o outro se aproximando desses limites:
O gráfico que acompanha mostra a diferença entre a média aritmética e a média geométrica para os parâmetros de forma e de 0 a 2. Apesar do fato de que a diferença entre elas aproxima-se de zero conforme e aproximam-se do infinito e que a diferença se torna larga para valores de e aproximando-se de zero, pode-se observar uma assimetria evidente da média geométrica com respeito aos parâmetros e . A diferença entre a média geométrica e a média aritmética é maior para valores pequenos de em relação a do que quando trocando as magnitudes de e .
Medidas de dispersão estatísticas
Variança[14]
A variança é o valor de uma distribuição beta com uma distribuição aleatória de variável X com os parâmetros α e β é
Tendo que α=β e através da expressão anterior tem-se que:
Quanto mais próximo de zero for α = β a variança tende a diminuir. Quando α = β = 0 tem se que o ponto máximo da variança, var(x)=1/4. A distribuição beta é parametrizada através de sua média μ (0 <μ <1) e tamanho de amostra: ν = α + β (ν> 0), usando estás variáveis tem-se que a variança é dada por:
Como ν = (α + β) > 0 e var(X) < μ(1 − μ). Então uma distribuição simétrica (média) é quando μ=1/2, tendo então:
Referências
↑ abcdJohnson, Norman L.; Kotz, Samuel; Balakrishnan, N. (1995). «21:Beta Distributions». Continuous Univariate Distributions Vol. 2 2 ed. [S.l.]: Wiley. ISBN 978-0-471-58494-0
↑Keeping, E. S. (2010). Introduction to Statistical Inference. [S.l.]: Dover Publications. ISBN 978-0486685021
↑ abWadsworth, George P. and Joseph Bryan (1960). Introduction to Probability and Random Variables. [S.l.]: McGraw-Hill
↑Hahn, Gerald J.; Shapiro, S. (1994). Statistical Models in Engineering (Wiley Classics Library). [S.l.]: Wiley-Interscience. ISBN 978-0471040651
↑ abcFeller, William (1971). An Introduction to Probability Theory and Its Applications, Vol. 2. [S.l.]: Wiley. ISBN 978-0471257097
↑ abGupta, Arjun K. (2004). Handbook of Beta Distribution and Its Applications. [S.l.]: CRC Press. ISBN 978-0824753962
↑Panik, Michael J (2005). Advanced Statistics from an Elementary Point of View. [S.l.]: Academic Press. ISBN 978-0120884940
↑ abRose, Colin; Smith, Murray D. (2002). Mathematical Statistics with MATHEMATICA. [S.l.]: Springer. ISBN 978-0387952345
↑Kruschke, John K. (2011). Doing Bayesian data analysis: A tutorial with R and BUGS. [S.l.]: Academic Press / Elsevier. p. 83. ISBN 978-0123814852
↑Berger, James O. (2010). Statistical Decision Theory and Bayesian Analysis 2 ed. [S.l.]: Springer. ISBN 978-1441930743
↑Kerman J. (2011) "A closed-form approximation for the median of the beta distribution". Arxiv
↑Mosteller, Frederick and John Tukey (1977). Data Analysis and Regression: A Second Course in Statistics. [S.l.]: Addison-Wesley Pub. Co.,. p. 207. ISBN 978-0201048544
↑Feller, William (1968). An Introduction to Probability Theory and Its Applications. 1 3 ed. [S.l.: s.n.] ISBN 978-0471257080
↑«Beta distribution». Wikipedia (em inglês). 1 de novembro de 2017



![{\displaystyle x\in [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/64a15936df283add394ab909aa7a5e24e7fb6bb2)




![{\displaystyle \operatorname {E} [X]={\frac {\alpha }{\alpha +\beta }}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/64edc7514f5611e9e4650f3584152ab3ac0bb811)
![{\displaystyle \operatorname {E} [\ln X]=\psi (\alpha )-\psi (\alpha +\beta )}](https://wikimedia.org/api/rest_v1/media/math/render/svg/350f451e381db241e3b1ec2cc9ba84c2ebf27e93)
![{\displaystyle I_{\frac {1}{2}}^{[-1]}(\alpha ,\beta )}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6ed1a5ad785f6fe3ff39e46dd808964ee7ba8d73)



![{\displaystyle \operatorname {var} [X]={\frac {\alpha \beta }{(\alpha +\beta )^{2}(\alpha +\beta +1)}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6c2367c268f610193119758414345f42b6958e0c)
![{\displaystyle \operatorname {var} [\ln X]=\psi _{1}(\alpha )-\psi _{1}(\alpha +\beta )}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e396e8700267735eb741f73e8906445579c43bc6)

![{\displaystyle {\frac {6[(\alpha -\beta )^{2}(\alpha +\beta +1)-\alpha \beta (\alpha +\beta +2)]}{\alpha \beta (\alpha +\beta +2)(\alpha +\beta +3)}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/eea65a8d7c9e00ba6299b727eab679117776f41e)
![{\displaystyle {\begin{matrix}\ln \mathrm {B} (\alpha ,\beta )-(\alpha -1)\psi (\alpha )-(\beta -1)\psi (\beta )\\[0.5em]+(\alpha +\beta -2)\psi (\alpha +\beta )\end{matrix}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4c89e36ccbf7522eba17d6e5ddb267e7cef46b8e)

![{\displaystyle [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d)








































![{\displaystyle x=I_{\frac {1}{2}}^{[-1]}(\alpha ,\beta )}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2ca6046e74e5db71ed2e8aa0a35783c4fc2db15a)

















![{\displaystyle {\begin{aligned}\mu =\operatorname {E} [X]&=\int _{0}^{1}xf(x;\alpha ,\beta )\,dx\\&=\int _{0}^{1}x\,{\frac {x^{\alpha -1}(1-x)^{\beta -1}}{\mathrm {B} (\alpha ,\beta )}}\,dx\\&={\frac {\alpha }{\alpha +\beta }}\\&={\frac {1}{1+{\frac {\beta }{\alpha }}}}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e9137834d9d47360ed6c23550c6236fed5fd35f7)















![{\displaystyle \ln G_{X}=\operatorname {E} [\ln X]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/64b67cb73b90bc0e09ba41003b44f84b6e1d3feb)
![{\displaystyle {\begin{aligned}\operatorname {E} [\ln X]&=\int _{0}^{1}\ln x\,f(x;\alpha ,\beta )\,dx\\[4pt]&=\int _{0}^{1}\ln x\,{\frac {x^{\alpha -1}(1-x)^{\beta -1}}{\mathrm {B} (\alpha ,\beta )}}\,dx\\[4pt]&={\frac {1}{\mathrm {B} (\alpha ,\beta )}}\,\int _{0}^{1}{\frac {\partial x^{\alpha -1}(1-x)^{\beta -1}}{\partial \alpha }}\,dx\\[4pt]&={\frac {1}{\mathrm {B} (\alpha ,\beta )}}{\frac {\partial }{\partial \alpha }}\int _{0}^{1}x^{\alpha -1}(1-x)^{\beta -1}\,dx\\[4pt]&={\frac {1}{\mathrm {B} (\alpha ,\beta )}}{\frac {\partial \mathrm {B} (\alpha ,\beta )}{\partial \alpha }}\\[4pt]&={\frac {\partial \ln \mathrm {B} (\alpha ,\beta )}{\partial \alpha }}\\[4pt]&={\frac {\partial \ln \Gamma (\alpha )}{\partial \alpha }}-{\frac {\partial \ln \Gamma (\alpha +\beta )}{\partial \alpha }}\\[4pt]&=\psi (\alpha )-\psi (\alpha +\beta )\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cd9db519e08e3c72cd6f9e2f0c90a7c57bdba035)

![{\displaystyle G_{X}=e^{\operatorname {E} [\ln X]}=e^{\psi (\alpha )-\psi (\alpha +\beta )}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c93ffa7f0155fa3816fcb151c3eb677700aabca2)





![{\displaystyle var(X)=E[x-\mu ^{2}]={\alpha \beta \over (\alpha +\beta )^{2}(\alpha +\beta +1)}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/84dc373c2f4bcf7a7388d66eb3ccca7bbb0af2aa)



 Portal de probabilidade e estatística
Portal de probabilidade e estatística Portal da matemática
Portal da matemática











