Coeficiente de correlação de postos de Spearman
| Estatística |
|---|
 |
|
|
Em estatística, o coeficiente de correlação de postos de Spearman ou rô de Spearman, que recebe este nome em homenagem ao psicólogo e estatístico Charles Spearman, frequentemente denotado pela letra grega (rô) ou , é uma medida não paramétrica de correlação de postos (dependência estatística entre a classificação de duas variáveis). O coeficiente avalia com que intensidade a relação entre duas variáveis pode ser descrita pelo uso de uma função monótona.[1] A correlação de Spearman entre duas variáveis é igual à correlação de Pearson entre os valores de postos daquelas duas variáveis. Enquanto a correlação de Pearson avalia relações lineares, a correlação de Spearman avalia relações monótonas, sejam elas lineares ou não.[2] Se não houver valores de dados repetidos, uma correlação de Spearman perfeita de +1 ou -1 ocorre quando cada uma das variáveis é uma função monótona perfeita da outra.


Intuitivamente, a correlação de Spearman entre duas variáveis será alta quando observações tiverem uma classificação semelhante (ou idêntica no caso da correlação igual a 1) entre as duas variáveis, isto é, a posição relativa das observações no interior da variável (1º, 2º, 3º, etc.), e baixa quando observações tiverem uma classificação dessemelhante (ou completamente oposta no caso da correlação igual a -1) entre as duas variáveis.
O coeficiente de Spearman é apropriado tanto para variáveis contínuas, como para variáveis discretas, incluindo variáveis ordinais.[3] Tanto o de Spearman, como o de Kendall pode ser formulados como casos especiais de um coeficiente de correlação mais geral.

Definição e cálculo



O coeficiente de correlação de Spearman é definido como o coeficiente de correlação de Pearson entre variáveis classificadas em postos.[4]
Para uma amostra de tamanho , os dados brutos são convertidos em postos e é computado a partir de:



- em que
- denota o usual coeficiente de correlação de Pearson, mas aplicado às variáveis em postos;
- é a covariância das variáveis em postos;
- e são os desvios padrão das variáveis em postos.[5]




Apenas se todos os postos forem números inteiros distintos, o coeficiente pode ser calculado usando a fórmula popular:
- em que
- é a diferença entre os dois postos de cada observação;
- é o número de observações.[6][7]


Quando há valores idênticos, geralmente se atribui a cada valor um posto fracionário igual à média de suas posições na ordem ascendente dos valores, que é equivalente ao cálculo da média de todas as permutações possíveis.[8]
Se valores repetidos estiverem presentes nos conjuntos de dados, a equação produz resultados incorretos. Apenas se, em ambas as variáveis, todos os postos forem distintos, então, (vide número tetraédrico ). A primeira equação — normalizando pelo desvio padrão — pode ser usada até mesmo quando os postos forem normalizados a ("postos relativos"), porque não é sensível tanto à translação, quanto ao escalonamento linear.


![{\displaystyle [0;1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bc3bf59a5da5d8181083b228c8933efbda133483)
Este método também não deve ser usado em casos em que o conjunto de dados estiver truncado, isto é, quando o coeficiente de correlação de Spearman for desejado para os registros do topo (seja pelos postos pré-mudança, pelos postos pós-mudança ou ambos). Neste caso, deve-se usar a fórmula do coeficiente de correlação de Pearson descrita acima.

O erro padrão do coeficiente foi determinado pelo estatístico britânico Karl Pearson em 1907 e pelo matemático britânico Thorold Gosset em 1920, sendo:


Quantidades relacionadas
 |  |

 Ver artigo principal: Correlação
Ver artigo principal: CorrelaçãoHá várias outras medidas numéricas que quantificam a intensidade da dependência estatística entre parers de observações. A mais comum é o coeficiente de correlação produto-momento de Pearson, que é um método de correlação semelhante ao coeficiente de correlação de postos de Spearman, que mede as relações "lineares" entre números brutos, não entre seus postos.
Um nome alternativo para a correlação de postos de Spearman é "correlação de grau".[9] Nesta denominação, o "posto" de uma observação é substituído pelo "grau". Em distribuições contínuas, o grau de uma observação é, por convenção, sempre uma metade menor que o posto. Assim, as correlações entre graus e postos são iguais neste caso. De forma mais generalizada, o "grau" de uma observação é proporcional ao valor estimado da fração de uma população menor que um dado valor, com o ajuste da meia-observação nos valores observados. Assim, isto corresponde a um tratamento possível de postos empatados. Ainda que incomum, o termo "correlação de grau" ainda está em uso.[10]
Interpretação
O sinal da correlação de Spearman indica a direção da associação entre (a variável independente) e (a variável dependente). Se tende a aumentar quando aumenta, o coeficiente de correlação de Spearman é positivo. Se tende a diminuir quando aumenta, o coeficiente de correlação de Spearman é negativo. Um coeficiente de Spearman igual a zero indica que não há tendência de que aumente ou diminua quando aumenta. A correlação de Spearman aumenta em magnitude conforme e ficam mais próximas de serem funções monótonas perfeitas uma da outra. Quando e são perfeitamente monotonamente relacionadas, o coeficiente de correlação de Spearman se torna 1. Uma relação crescente monótona perfeita implica que, para quaisquer dois pares de valores de dados e , Xi − Xj e Yi − Yj terão sempre o mesmo sinal. Uma relação decrescente monótona perfeita implica que estas diferenças terão sempre sinais opostos.

O coeficiente de correlação de Spearman é frequentemente descrito como sendo "não paramétrico". Isto pode ter dois sentidos. Em primeiro lugar, uma correlação de Spearman perfeita ocorre quando e estão relacionados por qualquer função monótona, em contraste com a correlação de Pearson, que só dá um valor perfeito quando e estão relacionadas por uma função linear. O outro sentido em que a correlação de Spearman é não paramétrica se refere ao fato de que sua exata distribuição de amostragem pode ser obtida sem conhecimento (isto é, sem informação sobre os parâmetros) quanto à distribuição de probabilidade conjunta de e .[11]
Exemplo
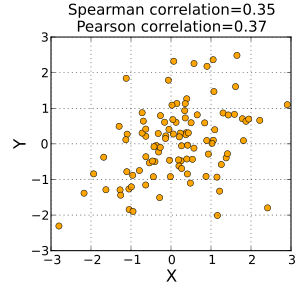
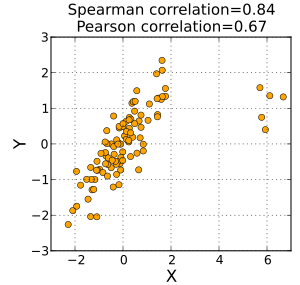
Neste exemplo, os dados brutos na tabela abaixo são usados para calcular a correlação entre o QI de uma pessoa e o número de horas em que assiste televisão por semana.
| QI, | Horas de TV por semana, |
|---|---|
| 106 | 7 |
| 86 | 0 |
| 100 | 27 |
| 101 | 50 |
| 99 | 28 |
| 103 | 29 |
| 97 | 20 |
| 113 | 12 |
| 112 | 6 |
| 110 | 17 |


Primeiro, é necessário achar o valor do termo . Para fazer isto, executam-se os seguintes passos, refletidos na tabela abaixo:

- Ordene os dados de acordo com a primeira coluna (). Crie uma nova coluna e atribua a esta coluna os valores dos postos ;
- Em seguida, ordene os dados de acordo com a segunda coluna (). Crie uma quarta coluna e, analogamente, atribua a esta coluna os valores dos postos ;
- Crie uma quinta coluna para conter as diferenças entre os postos das duas colunas e ;
- Crie uma última coluna para conter os quadrados dos valores da coluna .




| QI, | Horas de TV por semana, | posto | posto | ||
|---|---|---|---|---|---|
| 86 | 0 | 1 | 1 | 0 | 0 |
| 97 | 20 | 2 | 6 | −4 | 16 |
| 99 | 28 | 3 | 8 | −5 | 25 |
| 100 | 27 | 4 | 7 | −3 | 9 |
| 101 | 50 | 5 | 10 | −5 | 25 |
| 103 | 29 | 6 | 9 | −3 | 9 |
| 106 | 7 | 7 | 3 | 4 | 16 |
| 110 | 17 | 8 | 5 | 3 | 9 |
| 112 | 6 | 9 | 2 | 7 | 49 |
| 113 | 12 | 10 | 4 | 6 | 36 |
Calculados os valores , são somados para encontrar . O valor de é 10. Agora, estes valores podem ser substituidos na equação :



o que resulta em ρ = −29/165 = −0,175757575... com um valor-p igual a 0,627188, usando a distribuição t de Student.
Este valor baixo mostra que a correlação entre QI e número de horas na frente da TV é muito baixa, ainda que o valor negativo sugira que, quanto mais tempo se passa assistindo televisão, mais baixo o QI. No caso de empates nos dados originais, esta fórmula não deve ser usada. Em vez disso, o coeficiente de correlação de Pearson deve ser calculado nos postos (quando se atribuem postos aos empates, como descrito acima).
Determinação da significância
Uma abordagem para testar se um valor observado de é significantemente diferente de zero ( sempre se manterá entre -1 e 1) consiste em calcular a probabilidade de que seria maior ou igual ao observado, dada a hipótese nula, ao usar um teste de permutação. Uma vantagem desta abordagem é que ela automaticamente leva em conta o número de valores empatados de dados na amostra e a forma como são tratados ao computar a correlação de postos.[12]

Uma abordagem faz paralelo ao uso da transformação de Fisher no caso do coeficiente de correlação produto-momento de Pearson, isto é, intervalos de confiança e testes de hipóteses relativos ao valor da população podem ser conduzidos usando a transformação de Fisher:[13]

Se for a transformação de Fisher de , o coeficiente de correlação de postos de Spearman amostral, e for o tamanho da amostra, então:


é um escore padronizado para que segue aproximadamente uma distribuição normal padrão sob a hipótese nula da independência estatística ().[14][15]

Pode-se também testar por significância usando:

que é aproximadamente distribuído como a distribuição t de Student com graus de liberdade sob a hipótese nula.[16] Uma justificação para este resultado se baseia em um argumento de permutação.[17]

Uma generalização do coeficiente de Spearman é útil na situação em que há três ou mais condições, uma quantidade de sujeitos é toda observada em cada uma delas e se prevê que as observações terão uma ordem particular. Por exemplo, cada sujeito deste grupo será avaliado três vezes fazendo a mesma tarefa e se prevê que a performance melhorará a cada avaliação. Um teste da significância da tendência entre condições nesta situação foi desenvolvido por Ellis Batten Page, sendo usualmente chamado de teste de tendência de Page para alternativas ordenadas.[18]
Análise de correspondência baseada no rô de Spearman
A análise de correspondência clássica é um método estatístico que dá um escore para todo valor de duas variáveis nominais. Desta forma, o coeficiente de correlação de Pearson entre eles é maximizado.
Há um equivalente deste método, chamado de análise de correspondência de grau, que maximiza o rô de Spearman e o tau de Kendall.[19]
Ver também
- Coeficiente de correlação de Pearson
- Coeficiente de correlação tau de Kendall
- Desigualdade do rearranjo
Referências
- ↑ Spearman, C. (1904). «The Proof and Measurement of Association between Two Things». The American Journal of Psychology. 15 (1): 72–101. doi:10.2307/1412159
- ↑ Kendall, Maurice George; Gibbons, Jean Dickinson (1990). Rank correlation methods (em inglês). [S.l.]: E. Arnold
- ↑ Lehman, Ann; O'Rourke, Norm; Hatcher, Larry; Stepanski, Edward (2013). JMP for Basic Univariate and Multivariate Statistics: Methods for Researchers and Social Scientists, Second Edition (em inglês). [S.l.]: SAS Institute. ISBN 9781612906034
- ↑ Myers, Jerome L.; Well, Arnold D.; Jr, Robert F. Lorch (11 de janeiro de 2013). Research Design and Statistical Analysis: Third Edition (em inglês). [S.l.]: Routledge. ISBN 9781135811631
- ↑ Daniel, Wayne W. (30 de junho de 2000). Applied Nonparametric Statistics (em inglês). [S.l.]: Duxbury. ISBN 9780534381943
- ↑ Hollander, Myles; Wolfe, Douglas A.; Chicken, Eric (25 de novembro de 2013). Nonparametric Statistical Methods (em inglês). [S.l.]: John Wiley & Sons. ISBN 9781118553299
- ↑ Spiegel, M. R. (1985). Estatistica; resumo da teoria 875 problemas resolvidos 619 problemas propostos. [S.l.]: Fundacao CARGILL
- ↑ Dodge, Yadolah (15 de abril de 2008). The Concise Encyclopedia of Statistics (em inglês). [S.l.]: Springer Science & Business Media. ISBN 9780387317427
- ↑ Yule, George Udny; Kendall, Maurice (1950). An Introduction to the Theory of Statistics. G. Udny Yule, ... and M.G. Kendall, ... 14th Edition Revised and Enlarged (em inglês). [S.l.]: C. Griffin
- ↑ Piantadosi, Julia; Howlett, Phil; Boland, John (maio de 2007). «Matching the grade correlation coefficient using a copula with maximum disorder». Journal of Industrial and Management Optimization. 3 (2). Consultado em 19 de julho de 2017. Arquivado do original em 3 de dezembro de 2013
- ↑ Corder, Gregory W.; Foreman, Dale I. (20 de setembro de 2011). Nonparametric Statistics for Non-Statisticians: A Step-by-Step Approach (em inglês). [S.l.]: John Wiley & Sons. ISBN 9781118211250
- ↑ Bonett, Douglas G.; Wright, Thomas A. (1 de março de 2000). «Sample size requirements for estimating pearson, kendall and spearman correlations». Psychometrika (em inglês). 65 (1): 23–28. ISSN 0033-3123. doi:10.1007/BF02294183
- ↑ Caruso, John C.; Cliff, Norman (2 de julho de 2016). «Empirical Size, Coverage, and Power of Confidence Intervals for Spearman's Rho». Educational and Psychological Measurement (em inglês). 57 (4): 637–654. doi:10.1177/0013164497057004009
- ↑ Choi, S. C. (1 de dezembro de 1977). «Tests of equality of dependent correlation coefficients». Biometrika. 64 (3): 645–647. ISSN 0006-3444. doi:10.1093/biomet/64.3.645
- ↑ Fieller, E. C.; Hartley, H. O.; Pearson, E. S. (1 de dezembro de 1957). «TESTS FOR RANK CORRELATION COEFFICIENTS. I». Biometrika. 44 (3-4): 470–481. ISSN 0006-3444. doi:10.1093/biomet/44.3-4.470
- ↑ Press, William H.; Teukolsky, Saul A.; Vetterling, William T.; Flannery, Brian P. (7 de fevereiro de 2002). Numerical Recipes in C++: The Art of Scientific Computing (em inglês). [S.l.]: Cambridge University Press. ISBN 9780521750332
- ↑ The Advanced Theory of Statistics. Vol. 2: Inference and: Relationsship (em inglês). [S.l.]: Griffin. 1973
- ↑ Page, Ellis Batten (1 de março de 1963). «Ordered Hypotheses for Multiple Treatments: A Significance Test for Linear Ranks». Journal of the American Statistical Association. 58 (301): 216–230. ISSN 0162-1459. doi:10.2307/2282965
- ↑ Kowalczyk, Teresa; Pleszczynska, Elzbieta; Ruland, Frederick (6 de dezembro de 2012). Grade Models and Methods for Data Analysis: With Applications for the Analysis of Data Populations (em inglês). [S.l.]: Springer. ISBN 9783540399285
Ligações externas
- Cópulas vs. Correlações por Eric Torkia para Crystal Ball Analytics Services (em inglês)
- Tabela de valores críticos de ρ para significância com amostras pequenas no portal da Universidade de Sussex (em inglês)
- Fórmula usada quando há empates no VassarStats (em inglês)
- Coeficiente de correlação de postos de Spearman no Handbook of Biological Statistics (em inglês)
 Portal de probabilidade e estatística
Portal de probabilidade e estatística









