Indice di correlazione di Pearson
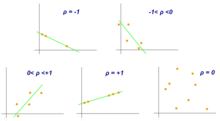
In statistica, l'indice di correlazione di Pearson (anche detto coefficiente di correlazione lineare[1], coefficiente di correlazione di Pearson o coefficiente di correlazione di Bravais-Pearson) tra due variabili statistiche è un indice che esprime un'eventuale relazione di linearità tra esse.[1]
Secondo la disuguaglianza di Cauchy-Schwarz ha un valore compreso tra e dove corrisponde alla perfetta correlazione lineare positiva, corrisponde a un'assenza di correlazione lineare e corrisponde alla perfetta correlazione lineare negativa. Fu sviluppato da Karl Pearson da un'idea introdotta da Francis Galton nel 1880; la formula matematica fu derivata e pubblicata da Auguste Bravais nel 1844.[2][3][4] La denominazione del coefficiente è anche un esempio della legge di Stigler.




Definizione
Date due variabili statistiche e , l'indice di correlazione di Pearson è definito come la loro covarianza divisa per il prodotto delle deviazioni standard delle due variabili:



dove è la covarianza tra e e sono le due deviazioni standard.


Il coefficiente assume sempre valori compresi tra e [5]


Correlazione e indipendenza
Nella pratica si distinguono vari "tipi" di correlazione.
- Se , le variabili e si dicono direttamente correlate, oppure correlate positivamente;
- se , le variabili e si dicono incorrelate;
- se , le variabili e si dicono inversamente correlate, oppure correlate negativamente.



Inoltre per la correlazione diretta (e analogamente per quella inversa) si distingue:
- se si ha correlazione debole;
- se si ha correlazione moderata;
- se si ha correlazione forte.



Se le due variabili sono indipendenti allora l'indice di correlazione vale 0. Non vale la conclusione opposta: in altri termini, l'incorrelazione è condizione necessaria ma non sufficiente per l'indipendenza. Per esempio data la distribuzione
| X: | -3 | -2 | -1 | 0 | 1 | 2 | 3 |
|---|---|---|---|---|---|---|---|
| Y: | 9 | 4 | 1 | 0 | 1 | 4 | 9 |
abbiamo che e non sono indipendenti in quanto legate dalla relazione , ma .

L'ipotesi di assenza di autocorrelazione è più restrittiva ed implica quella di indipendenza fra due variabili.
L'indice di correlazione vale in presenza di correlazione lineare positiva perfetta (cioè , con ), mentre vale in presenza di correlazione lineare negativa perfetta (cioè , con ).



Valori prossimi a (o ) possono essere misurati anche in presenza di relazioni non lineari. Per esempio, la seguente relazione quadratica:
| X: | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Y: | 1 | 4 | 9 | 16 |
produce un coefficiente .

Generalizzazione a più di due variabili
Gli indici di correlazione di variabili possono essere presentati in una matrice di correlazione, che è una matrice quadrata di dimensione avente sia sulle righe che sulle colonne le variabili oggetto di studio. La matrice è simmetrica, cioè , e i coefficienti sulla diagonale valgono in quanto





Proprietà matematiche
Un valore dell'indice di correlazione uguale a o corrisponde a punti che si trovano esattamente su una linea retta. Il coefficiente di correlazione di Pearson è simmetrico:

Una proprietà matematica caratteristica del coefficiente di correlazione di Pearson è che non varia rispetto ai cambiamenti singoli della posizione e della scala delle due variabili. Cioè, possiamo trasformare in e trasformare in dove e sono costanti reali con senza modificare il coefficiente di correlazione.





Esempio in R
Utilizzando il linguaggio di programmazione R si vuole calcolare l'indice di correlazione di Pearson tra la variabile Fertility rate, total (births per woman) e la variabile GDP per capita (current US$) nel 2020 , fornite dalla Banca Mondiale qui : https://databank.worldbank.org/reports.aspx?source=world-development-indicators . Per fare questo si utilizza la funzione cor nel seguente modo :
library(dplyr) World_Bank_Data <- read.csv("World_Bank_Data.csv") df1 <- World_Bank_Data %>% filter(Series.Name=="Fertility rate, total (births per woman)") %>% select(Country.Name,X2020..YR2020.) colnames(df1)[2] <- "Numero di figli per donna" df2 <- World_Bank_Data %>% filter(Series.Name=="GDP per capita (current US$)" ) %>% select(Country.Name,X2020..YR2020.) colnames(df2)[2] <- "Pil procapite" df1 <- merge(df1,df2 , by="Country.Name") df1$`Numero di figli per donna` <- as.numeric(df1$`Numero di figli per donna`) df1$`Pil procapite` <- as.numeric(df1$`Pil procapite`) df1 <- df1[-which(is.na(df1$`Pil procapite`)),] df1 <- df1[-which(is.na(df1$`Numero di figli per donna`)),] cor(df1$`Numero di figli per donna`,df1$`Pil procapite`,)
-0.4601806
Note
- ^ a b Glossario Istat, su www3.istat.it (archiviato dall'url originale il 31 dicembre 2011).
- ^ (F. Galton) (24 September 1885), "The British Association: Section II, Anthropology: Opening address by Francis Galton, F.R.S., etc., President of the Anthropological Institute, President of the Section," Nature, 32 (830) : 507–510..
- ^ Karl Pearson (20 June 1895) "Notes on regression and inheritance in the case of two parents," Proceedings of the Royal Society of London, 58 : 240–242..
- ^ Stigler, Stephen M. (1989). "Francis Galton's Account of the Invention of Correlation". Statistical Science. 4 (2): 73–79..
- ^ Ross, p. 117.
Bibliografia
- Sheldon M. Ross, Introduzione alla statistica, 2ª ed., Maggioli Editore, 2014, ISBN 8891602671.
Voci correlate
- Coefficiente di correlazione per ranghi di Spearman
- Coefficiente di correlazione per ranghi di Kendall
- Regressione lineare
- Correlazione (statistica)
- Karl Pearson
- Francis Galton, il primo a introdurre la lettera r (come abbreviazione di "regressione") anche se utilizzava un coefficiente diverso, in quanto normava usando lo scarto interquartile.
Collegamenti esterni
- (EN) Ken Stewart, Pearson’s correlation coefficient, su Enciclopedia Britannica, Encyclopædia Britannica, Inc.

- (EN) Eric W. Weisstein, Indice di correlazione di Pearson, su MathWorld, Wolfram Research.


| Controllo di autorità | GND (DE) 4165345-2 |
|---|
 Portale Economia
Portale Economia Portale Statistica
Portale Statistica









