Nella teoria delle probabilità la distribuzione di Student, o t di Student, è una distribuzione di probabilità continua che governa il rapporto tra due variabili aleatorie, la prima con distribuzione normale standard e la seconda, al quadrato, segue una distribuzione chi quadrato.
Questa distribuzione interviene nella stima della media di una popolazione che segue la distribuzione normale, e viene utilizzata negli omonimi test t di Student per la significatività e per ogni intervallo di confidenza della differenza tra due medie.
Storia
La distribuzione venne descritta nel 1908 da William Sealy Gosset, che pubblicò il suo risultato sotto lo pseudonimo "Student" perché la fabbrica di birra Guinness presso la quale era impiegato vietava ai propri dipendenti di pubblicare articoli affinché questi non divulgassero segreti di produzione. Il nome distribuzione di Student venne successivamente introdotto da Ronald Fisher.[2][3]
Definizione
La distribuzione di Student con parametro  (gradi di libertà) governa la variabile aleatoria
(gradi di libertà) governa la variabile aleatoria

dove  e
e  sono due variabili aleatorie indipendenti che seguono rispettivamente la distribuzione normale standard
sono due variabili aleatorie indipendenti che seguono rispettivamente la distribuzione normale standard  e la distribuzione chi quadro
e la distribuzione chi quadro  con gradi di libertà.
con gradi di libertà.
Stimatori
La media  e la varianza
e la varianza  di una popolazione
di una popolazione  possono essere stimate tramite un suo campione di
possono essere stimate tramite un suo campione di  elementi,
elementi,  con gli stimatori
con gli stimatori


Supponiamo che le variabili aleatorie che compongono il campione siano indipendenti e distribuite normalmente, allora  è una variabile normale
è una variabile normale  con valore atteso e varianza
con valore atteso e varianza  . Pertanto la variabile così definita
. Pertanto la variabile così definita

seguirà una distribuzione normale standard, . Il problema è che spesso non si conosce , pertanto dovremo avere a che fare con uno stimatore della varianza come  .
.
Dimostreremo che la seguente variabile aleatoria

segue una distribuzione chi-quadro con  gradi di libertà,
gradi di libertà,  .
.
Le due variabili aleatorie e  sono indipendenti, per il teorema di Cochran.
sono indipendenti, per il teorema di Cochran.
Pertanto si definisce la variabile aleatoria

Tale variabile aleatoria segue una distribuzione di probabilità detta "t di Student".
Ricavare la distribuzione di t
Cominciamo con il dimostrare che è una variabile aleatoria di tipo chi-quadro. Ricordiamo che una distribuzione è una particolare variabile di tipo gamma definita come segue

dove  è la funzione Gamma di Eulero definita come
è la funzione Gamma di Eulero definita come
 con
con  per ogni
per ogni 
Una variabile chi-quadro con gradi di libertà si ottiene sommando variabili normali standard elevate al quadrato. Detto ciò partiamo dalla definizione della varianza campionaria e aggiungiamo e sottraiamo nell'argomento della sommatoria , il valore aspettato della variabile aleatoria  che coincide con quello della variabile aleatoria .
che coincide con quello della variabile aleatoria .

Definiamo i parametri  e
e  come
come  e riscriviamo la formula precedente
e riscriviamo la formula precedente

Ora possiamo esplicitare fuori dalle sommatorie tutti i termini che non dipendono da  , ossia e
, ossia e
![{\displaystyle (N-1)S^{2}=\sum _{i}(X_{i}-\mu )^{2}+N({\bar {X}}-\mu )^{2}-2({\bar {X}}-\mu )\sum _{i}(X_{i}-\mu )=\sum _{i}(X_{i}-\mu )^{2}+N({\bar {X}}-\mu )^{2}-2({\bar {X}}-\mu )\left[-N\mu +\sum _{i}X_{i}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cd62d94edd82ec0b11ead231f41fc6938fde2251)

sapendo che la somma su tutti gli è uguale a  . Dividendo ora a destra e a sinistra per otteniamo a destra delle variabili normali
. Dividendo ora a destra e a sinistra per otteniamo a destra delle variabili normali

Abbiamo quindi ottenuto a sinistra una variabile che precedentemente avevamo indicato con , mentre a destra abbiamo somme di variabili normali standard al quadrato, coincidenti con una variabile chi quadro con gradi di libertà e un'altra variabile normale anch'essa standard elevata al quadrato, ossia una variabile chi-quadro ad un solo grado di libertà. Sapendo che somme di variabili di tipo chi-quadro con e  gradi di libertà corrispondono ancora ad una variabile chi-quadro con
gradi di libertà corrispondono ancora ad una variabile chi-quadro con  gradi di libertà otteniamo che la funzione di densità di probabilità di è di tipo chi-quadro con gradi di libertà.
gradi di libertà otteniamo che la funzione di densità di probabilità di è di tipo chi-quadro con gradi di libertà.
Pertanto ora iniziamo a dire che

dove  è il numero di gradi di libertà, e che
è il numero di gradi di libertà, e che

Conosciuta la variabile aleatoria , essa si riduce difatti ad un parametro moltiplicativo per la normale. Dalla definizione di probabilità condizionata si ha

dove

è una distribuzione chi-quadro con gradi di libertà. Quindi

Notiamo che la funzione di distribuzione cercata non è altro che una funzione marginale di  , pertanto si ha
, pertanto si ha


Ponendo una sostituzione con l'argomento dell'esponenziale, mantenendolo però negativo

otteniamo

l'integrale definito ha come risultato la funzione Gamma di Eulero stessa

Pertanto otteniamo al fine il nostro risultato

Notiamo che il limite di questa successione di funzioni per  è
è

Sapendo che il primo limite ha come risultato  e il secondo tende a
e il secondo tende a  .
.
In pratica, prendendo una popolazione di numerosità molto grande, la variabile aleatoria t tende ad essere una normale standard.
Caratteristiche
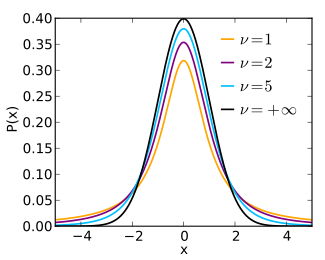
La distribuzione di Student con gradi di libertà è simmetrica, perché lo è la distribuzione normale standard mentre la distribuzione chi quadrato che funge da "parametro casuale di scala" non produce effetti di distorsione di tale simmetria.
La sua funzione di densità di probabilità è

dove  la funzione beta.
la funzione beta.
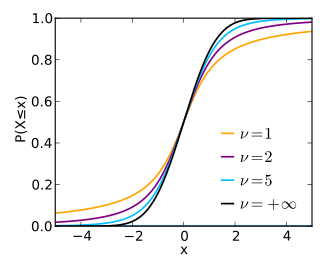
La sua funzione di ripartizione è

dove  è la funzione beta incompleta regolarizzata con
è la funzione beta incompleta regolarizzata con

Per  i momenti (semplici o centrali, in quanto coincidono per una PDF simmetrica) di ordine della distribuzione sono
i momenti (semplici o centrali, in quanto coincidono per una PDF simmetrica) di ordine della distribuzione sono

In particolare, oltre alla speranza matematica  e all'indice di asimmetria
e all'indice di asimmetria  (per
(per  ) predetti dalla simmetria della distribuzione, si trovano:
) predetti dalla simmetria della distribuzione, si trovano:
- la varianza
 per
per 
- l'indice di curtosi
 per
per 
Consideriamo infine un ultimo parametro: la larghezza a metà altezza. Per una variabile  di Student abbiamo che il picco della funzione è nel suo valore atteso, ossia in
di Student abbiamo che il picco della funzione è nel suo valore atteso, ossia in  , dove la distribuzione ha valore massimo
, dove la distribuzione ha valore massimo

Per cui troviamo i valori di per i quali  assume altezza uguale a metà della massima assoluta.
assume altezza uguale a metà della massima assoluta.

Per cui

dove ha due soluzioni, come ci aspettavamo dalla simmetria della funzione, coincidenti a

Per cui la larghezza a mezza altezza della funzione è data da

Eseguendo il limite per troviamo un'espressione convergente a

che è l'equivalente della larghezza a metà altezza (FWHM) della normale standard. Viceversa per  otteniamo un FWHM = 2. Difatti per la distribuzione t di Student coincide con una distribuzione di Lorentz-Cauchy di parametri
otteniamo un FWHM = 2. Difatti per la distribuzione t di Student coincide con una distribuzione di Lorentz-Cauchy di parametri  dove la FWHM è per l'appunto uguale a
dove la FWHM è per l'appunto uguale a  .
.
Statistica
Intervallo di confidenza
La distribuzione di Student viene utilizzata per definire degli intervalli di confidenza per la media di una popolazione, sulla base degli stimatori puntuali e  della sua media e della sua varianza. Dall'equazione
della sua media e della sua varianza. Dall'equazione

si ha infatti

Scegliendo quindi dei quantili  per la distribuzione di Student con gradi di libertà, si ha
per la distribuzione di Student con gradi di libertà, si ha

cioè un intervallo di confidenza per la media con livello di confidenza  è:
è:
![{\displaystyle \left[{\bar {X}}-q_{\beta }{\sqrt {S_{n}^{2}/n}}\ ,\ {\bar {X}}-q_{\alpha }{\sqrt {S_{n}^{2}/n}}\ \right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ada3adca2ce1142808b0b3e8fb32c6c64c68039c) .
.
Qualora si considerino intervalli simmetrici si può utilizzare l'indice  definito da
definito da

ossia

e si ottiene l'intervallo di confidenza per con livello di confidenza 
![{\displaystyle \left[{\bar {X}}-z_{\alpha }{\sqrt {S_{n}^{2}/n}}\ ,\ {\bar {X}}+z_{\alpha }{\sqrt {S_{n}^{2}/n}}\ \right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b4cec8215c964ce8eca55b0f757eacc6872dd9c8)
Altre distribuzioni
La distribuzione di Student con parametro corrisponde alla distribuzione di Cauchy di parametri : entrambe regolano il rapporto  tra due variabili aleatorie indipendenti aventi distribuzione normale standard.
tra due variabili aleatorie indipendenti aventi distribuzione normale standard.
Al tendere di a infinito la distribuzione di Student con gradi di libertà converge alla distribuzione normale standard .
Se  è una variabile aleatoria con distribuzione t di Student di parametro , allora
è una variabile aleatoria con distribuzione t di Student di parametro , allora  segue la distribuzione di Fisher-Snedecor di parametri
segue la distribuzione di Fisher-Snedecor di parametri  .
.
Tabella dei quantili
La seguente tabella[4] esprime, in funzione del parametro (riga) e di particolari valori di (colonna), i quantili  per la distribuzione di Student di parametro :
per la distribuzione di Student di parametro :

L'ultima riga, indicata con "∞", si riferisce a una distribuzione normale standard.
| n\α | 0,90 | 0,95 | 0,975 | 0,99 | 0,995 | 0,9975 | 0,999 | 0,9995 |
| 1 | 3,078 | 6,314 | 12,706 | 31,821 | 63,657 | 127,321 | 318,309 | 636,619 |
| 2 | 1,886 | 2,920 | 4,303 | 6,965 | 9,925 | 14,089 | 22,327 | 31,599 |
| 3 | 1,638 | 2,353 | 3,182 | 4,541 | 5,841 | 7,453 | 10,215 | 12,924 |
| 4 | 1,533 | 2,132 | 2,776 | 3,747 | 4,604 | 5,598 | 7,173 | 8,610 |
| 5 | 1,476 | 2,015 | 2,571 | 3,365 | 4,032 | 4,773 | 5,893 | 6,869 |
| 6 | 1,440 | 1,943 | 2,447 | 3,143 | 3,707 | 4,317 | 5,208 | 5,959 |
| 7 | 1,415 | 1,895 | 2,365 | 2,998 | 3,499 | 4,029 | 4,785 | 5,408 |
| 8 | 1,397 | 1,860 | 2,306 | 2,896 | 3,355 | 3,833 | 4,501 | 5,041 |
| 9 | 1,383 | 1,833 | 2,262 | 2,821 | 3,250 | 3,690 | 4,297 | 4,781 |
| 10 | 1,372 | 1,812 | 2,228 | 2,764 | 3,169 | 3,581 | 4,144 | 4,587 |
| 11 | 1,363 | 1,796 | 2,201 | 2,718 | 3,106 | 3,497 | 4,025 | 4,437 |
| 12 | 1,356 | 1,782 | 2,179 | 2,681 | 3,055 | 3,428 | 3,930 | 4,318 |
| 13 | 1,350 | 1,771 | 2,160 | 2,650 | 3,012 | 3,372 | 3,852 | 4,221 |
| 14 | 1,345 | 1,761 | 2,145 | 2,624 | 2,977 | 3,326 | 3,787 | 4,140 |
| 15 | 1,341 | 1,753 | 2,131 | 2,602 | 2,947 | 3,286 | 3,733 | 4,073 |
| 16 | 1,337 | 1,746 | 2,120 | 2,583 | 2,921 | 3,252 | 3,686 | 4,015 |
| 17 | 1,333 | 1,740 | 2,110 | 2,567 | 2,898 | 3,222 | 3,646 | 3,965 |
| 18 | 1,330 | 1,734 | 2,101 | 2,552 | 2,878 | 3,197 | 3,610 | 3,922 |
| 19 | 1,328 | 1,729 | 2,093 | 2,539 | 2,861 | 3,174 | 3,579 | 3,883 |
| 20 | 1,325 | 1,725 | 2,086 | 2,528 | 2,845 | 3,153 | 3,552 | 3,850 |
| 21 | 1,323 | 1,721 | 2,080 | 2,518 | 2,831 | 3,135 | 3,527 | 3,819 |
| 22 | 1,321 | 1,717 | 2,074 | 2,508 | 2,819 | 3,119 | 3,505 | 3,792 |
| 23 | 1,319 | 1,714 | 2,069 | 2,500 | 2,807 | 3,104 | 3,485 | 3,768 |
| 24 | 1,318 | 1,711 | 2,064 | 2,492 | 2,797 | 3,091 | 3,467 | 3,745 |
| 25 | 1,316 | 1,708 | 2,060 | 2,485 | 2,787 | 3,078 | 3,450 | 3,725 |
| 26 | 1,315 | 1,706 | 2,056 | 2,479 | 2,779 | 3,067 | 3,435 | 3,707 |
| 27 | 1,314 | 1,703 | 2,052 | 2,473 | 2,771 | 3,057 | 3,421 | 3,690 |
| 28 | 1,313 | 1,701 | 2,048 | 2,467 | 2,763 | 3,047 | 3,408 | 3,674 |
| 29 | 1,311 | 1,699 | 2,045 | 2,462 | 2,756 | 3,038 | 3,396 | 3,659 |
| 30 | 1,310 | 1,697 | 2,042 | 2,457 | 2,750 | 3,030 | 3,385 | 3,646 |
| 40 | 1,303 | 1,684 | 2,021 | 2,423 | 2,704 | 2,971 | 3,307 | 3,551 |
| 50 | 1,299 | 1,676 | 2,009 | 2,403 | 2,678 | 2,937 | 3,261 | 3,496 |
| 60 | 1,296 | 1,671 | 2,000 | 2,390 | 2,660 | 2,915 | 3,232 | 3,460 |
| 100 | 1,290 | 1,660 | 1,984 | 2,364 | 2,626 | 2,871 | 3,174 | 3,390 |
| ∞ | 1,282 | 1,645 | 1,960 | 2,326 | 2,576 | 2,807 | 3,090 | 3,291 |
Note
- ^ (EN) Simon Hurst, The Characteristic Function of the Student-t Distribution, in Financial Mathematics Research Report No. FMRR006-95, Statistics Research Report No. SRR044-95 (archiviato dall'url originale il 18 febbraio 2010).
- ^ (EN) Student (William Sealy Gosset), The probable error of a mean (PDF), in Biometrika, vol. 6, n. 1, marzo 1908, pp. 1–-25, DOI:10.1093/biomet/6.1.1.
- ^ (EN) Ronald Fisher, Applications of "Student's" distribution (PDF), in Metron, vol. 5, 1925, pp. 90-–104 (archiviato dall'url originale il 13 aprile 2011).
- ^ Valori critici calcolati con la funzione qt(p,g) di R.
Voci correlate
Altri progetti
 Wikimedia Commons contiene immagini o altri file su Distribuzione t di Student
Wikimedia Commons contiene immagini o altri file su Distribuzione t di Student
Collegamenti esterni
- (EN) Student’s t distribution, su Enciclopedia Britannica, Encyclopædia Britannica, Inc.

- (EN) Eric W. Weisstein, Distribuzione t di Student, su MathWorld, Wolfram Research.
- Probability, Statistics and Estimation in inglese. I primi Studentes a pagina 112.
- Il test di Student di F. Scotti.
 Portale Matematica
Portale Matematica: accedi alle voci di Wikipedia che trattano di matematica
















 Portale Matematica: accedi alle voci di Wikipedia che trattano di matematica
Portale Matematica: accedi alle voci di Wikipedia che trattano di matematica









